JSON vs TOON: Save tokens on your LLMs 🪙
Discover TOON, the new format that promises to dethrone JSON for feeding LLMs and save you a fortune in tokens.
- Date
Hello everyone! 👋 Welcome back to the blog.
Today I’m here to talk about a topic that is on the lips of everyone working with Artificial Intelligence and LLMs (Large Language Models): token optimization. Because, my friends, in the world of AI, tokens are money 💸. Literally.
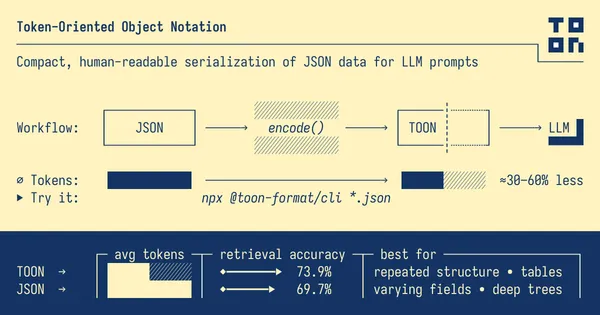
If you’ve been “tinkering” with models like GPT-4, Claude, or Gemini for a while, you’ll know that feeding the beast with structured data is our daily bread. Whether it’s for RAG (Retrieval-Augmented Generation), fine-tuning, or simply providing context, we need to pass data to the model. And this is where our old friend JSON has been the undisputed king… until now.
The problem with JSON: The “verbosity tax” 🐢
Don’t get me wrong, I love JSON. It’s readable, easy to parse, and universal. It has been the de facto standard for data exchange on the web for years. But when it comes to sending large amounts of data to an LLM, JSON has a “small” problem: it is extremely verbose.
Imagine you have a list of 1000 users. In JSON, you repeat the keys name, email, role, etc., 1000 times!
{
"users": [
{ "id": 1, "name": "Jorge", "role": "Developer", "active": true },
{ "id": 2, "name": "Maria", "role": "Designer", "active": false }
// ... imagine this repeated 1000 times 😱
]
}Every time you repeat "name":, you are spending tokens. Tokens that you could be using to give more context to the model or to get a longer response. It’s redundant structure that the model doesn’t need to see constantly to understand the data.
What is TOON? 🦸♂️
This is where TOON (Token-Oriented Object Notation) comes into play. It is a format designed specifically to be “token-friendly”. Its goal is to maintain the structure of the data but eliminate the syntactic redundancy that costs us so much on the API bill.
Think of TOON as a translation layer: you use JSON in your code (because it’s comfortable), but you encode it to TOON before sending it to the LLM.
TOON’s philosophy is simple but brilliant: it combines the indentation-based structure of YAML (for nested objects) with the tabular efficiency of CSV (for uniform arrays).
How does it work?
The key is to declare the structure only once and then “stream” the data.
Let’s see the previous example converted to TOON:
users[2]{id,name,role,active}:
1,Jorge,Developer,true
2,Maria,Designer,falseLook at the cleanliness! 🧹
users[2]: Explicitly declares the length of the array. This helps the LLM know if generation has been cut off or if data is missing.{id,name,role,active}: Defines the headers (the keys) only once.1,Jorge...: The data goes in rows, separated by commas, just like in a CSV.
We have eliminated all the quotes from the keys, the repetitive braces, and the repeated keys themselves. For an array of 2 elements it might not seem like much, but scale this to thousands of records and the difference is abysmal.
A more complex example: The best of both worlds 🌍
TOON is not just a glorified CSV. Its real power is seen when we mix objects and arrays. Look at this example taken from its official documentation, where we have a context (object) and lists of data (arrays):
In JSON:
{
"context": {
"task": "Our favorite hikes",
"location": "Pyrenees",
"season": "summer_2025"
},
"friends": ["ana", "luis", "sam"],
"hikes": [
{ "id": 1, "name": "Monte Perdido", "km": 15.5, "hard": true },
{ "id": 2, "name": "Aneto", "km": 12.2, "hard": true },
{ "id": 3, "name": "Cola de Caballo", "km": 18.0, "hard": false }
]
}In TOON:
context:
task: Our favorite hikes
location: Pyrenees
season: summer_2025
friends[3]: ana,luis,sam
hikes[3]{id,name,km,hard}:
1,Monte Perdido,15.5,true
2,Aneto,12.2,true
3,Cola de Caballo,18.0,falseHere we see the magic:
contextuses a YAML-like style (key-value with indentation).friendsis an array of primitives, super compact.hikesis an array of objects, rendered as a table.
The format automatically adapts to the structure of your data to be as efficient as possible.
Why use TOON? (Design Goals) 🎯
According to its creators, TOON has very clear design goals that make it ideal for LLMs:
- Token Efficiency: Reduces token usage by 30% to 60% compared to pretty-printed JSON.
- Schema-Aware: By including the array length
[N]and headers, we give explicit hints to the model. This reduces hallucinations and helps validate that the output is complete. - Human Readability: Unlike binary formats or extreme minification, TOON remains readable by us.
- Lossless: It is a lossless representation of the JSON data model. You can go from JSON -> TOON -> JSON without losing anything.
When to use it (and when NOT)? 🚦
Like any tool, it’s not a silver bullet. Here is my recommendation:
✅ Use it when:
- You have uniform arrays of objects (lists of products, users, logs, transactions). This is where TOON shines and destroys JSON in efficiency.
- Token cost is a concern (and when isn’t it?).
- You need to maximize the context window to fit more information.
❌ Do not use it when:
- Your data is very irregular or deeply nested without repetitive patterns. If every object has different keys, TOON cannot use its tabular format and ends up looking like YAML, losing its advantage.
- You need ultra-low latency in very small local models that might not have seen this format ever (although large models understand it perfectly with a proper prompt).
- It’s purely tabular and flat data: there a simple CSV might be even lighter (although TOON adds safety with types and lengths).
Benchmarks and Savings 📊
Preliminary tests are impressive. In typical RAG datasets, the savings are substantial.
🛒 E-commerce orders with nested structures ┊ Tabular: 33%
│
TOON █████████████░░░░░░░ 72,771 tokens
├─ vs JSON (−33.1%) 108,806 tokens
├─ vs JSON compact (+5.5%) 68,975 tokens
├─ vs YAML (−14.2%) 84,780 tokens
└─ vs XML (−40.5%) 122,406 tokens
🧾 Semi-uniform event logs ┊ Tabular: 50%
│
TOON █████████████████░░░ 153,211 tokens
├─ vs JSON (−15.0%) 180,176 tokens
├─ vs JSON compact (+19.9%) 127,731 tokens
├─ vs YAML (−0.8%) 154,505 tokens
└─ vs XML (−25.2%) 204,777 tokens
🧩 Deeply nested configuration ┊ Tabular: 0%
│
TOON ██████████████░░░░░░ 631 tokens
├─ vs JSON (−31.3%) 919 tokens
├─ vs JSON compact (+11.9%) 564 tokens
├─ vs YAML (−6.2%) 673 tokens
└─ vs XML (−37.4%) 1,008 tokens
──────────────────────────────────── Total ────────────────────────────────────
TOON ████████████████░░░░ 226,613 tokens
├─ vs JSON (−21.8%) 289,901 tokens
├─ vs JSON compact (+14.9%) 197,270 tokens
├─ vs YAML (−5.6%) 239,958 tokens
└─ vs XML (−31.0%) 328,191 tokensImagine reducing your OpenAI or Anthropic bill by half just by changing the input data format. 🤯
Conclusion
Optimization is key in this new era of AI. Tools like TOON help us be more efficient and build better products. It’s not just about saving money, but making our applications faster and capable of processing more information.
TOON is still young, but its value proposition is undeniable. If you are building data-intensive applications with LLMs, I encourage you to try it. You can find more information and the full documentation on their official website.
And you? Have you already tried alternative formats to JSON like YAML or XML for your prompts? Tell me on social media!
I hope you liked this post and that it helps you save a few tokens (and dollars). 😉
Greetings and see you in the next post! 🚀
Peace ✌️.

